


En lo que va de siglo, nuestra sociedad ha experimentado la creación e implementación de una economía basada en la información y el conocimiento, transformando el mundo un día a la vez, creando valor social y económico exponencial. En apenas dos décadas, la transformación de la información y el conocimiento en soluciones concretas, se ha convertido en la ecuación fundamental para la generación de valor, eficiencia, prosperidad y riqueza.
Pero antes de la información, existe la data. La data es un conjunto de números, símbolos, carácteres, palabras, códigos o gráficos que no tienen significado lógico, pero que puestos en contexto se puede convertir en información, que sí tiene un significado lógico.
La data se mide en bits, la información en unidades como tiempo y cantidad. Los seres humanos utilizamos la información para tomar decisiones, las computadoras utilizan fórmulas matemáticas, scripts de programación y aplicaciones de software para convertir la data en información, lo que nos permite ahorrar nuestro recurso más valioso: el tiempo.
Una de las características que tenemos los seres humanos es que evitamos las tareas repetitivas, siempre tratamos de usar atajos para ahorrar tiempo. Los métodos matemáticos que aprendemos a lo largo de la vida están precisamente impulsados por ese deseo de evitar la repetición. Por otro lado, las computadoras están diseñadas para hacer operaciones pequeñas, repetitivas e incrementales. Es por esta razón que crear un algoritmo computacional no es tarea fácil, porque debemos dejar atrás cómo operamos los humanos y pensar en cómo operan las máquinas.
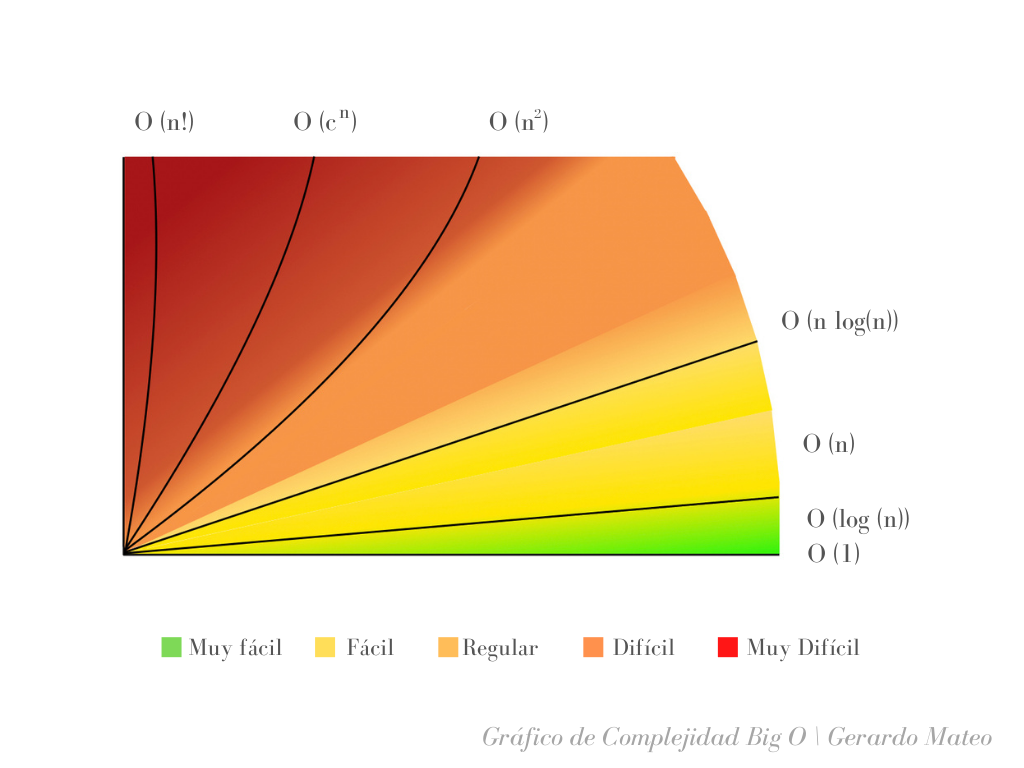
Esto se puede ver reflejado en el estudio de algoritmos computacionales, donde tenemos la función Cota Superior Asintótica o Big O Notation, que permite determinar la facilidad de ejecución de un algoritmo en base al tiempo y espacio requerido a medida que aumentan los valores de entrada en una función, que van desde — Constante, logarítmica, lineal, linearitmética:, cuadrática, exponencial y factorial.
Interesantemente, muchas veces para los seres humanos es más fácil crear un algoritmo computacional a partir de una función exponencial donde se agrupan las operaciones, mientras que para la máquina, una función logarítmica es más fácil de ejecutar, porque se puede desglosar en operaciones pequeñas pero repetitivas.
La aplicación de estas habilidades de las máquinas ha transformado la dinámica de cómo operamos como sociedad en distintas vertientes. Los beneficios más obvios incluyen la optimización de procesos repetitivos, la reducción del error humano, la toma de decisiones expeditas, y la disponibilidad de servicios 24/7.
Inteligencia artificial
Los dos grandes objetivos de las ciencias computacionales siempre han sido el de simplificar las cosas para los humanos, y el reducir la cantidad de recursos que se necesitan para realizar una tarea; el tiempo siendo el recurso más valioso. La inteligencia artificial (AI, por sus siglas en inglés), una de las ramas más importantes de las ciencias computacionales, se enfoca precisamente en eso: en proteger el tiempo humano, al habilitar a la máquina para que tome decisiones por sí misma. El aprendizaje de máquina o machine learning, un subconjunto de Inteligencia Artificial, se enfoca en el uso de técnicas estadísticas que permiten que las máquinas puedan aprender (mejorar con experiencia), sin tener que ser programadas explícitamente para eso.
El aprendizaje de máquina es aplicado por defecto en muchos de los sistemas y productos que utilizamos a diario, desde reconocimiento de imágenes y de voz, hasta recomendaciones de productos, vehículos autónomos y filtros de correo electrónico no deseado. El Aprendizaje de Máquina logra esto a través de tres métodos principales: (1) aprendizaje supervisado, (2) aprendizaje no supervisado, y (3) aprendizaje por refuerzo. un ejemplo de aprendizaje supervisado es aplicado en la clasificación de correo electrónico no deseado, basado en data que ya ha sido etiquetada previamente, y es usada como ejemplo por la máquina para determinar nuevos correos no deseados.
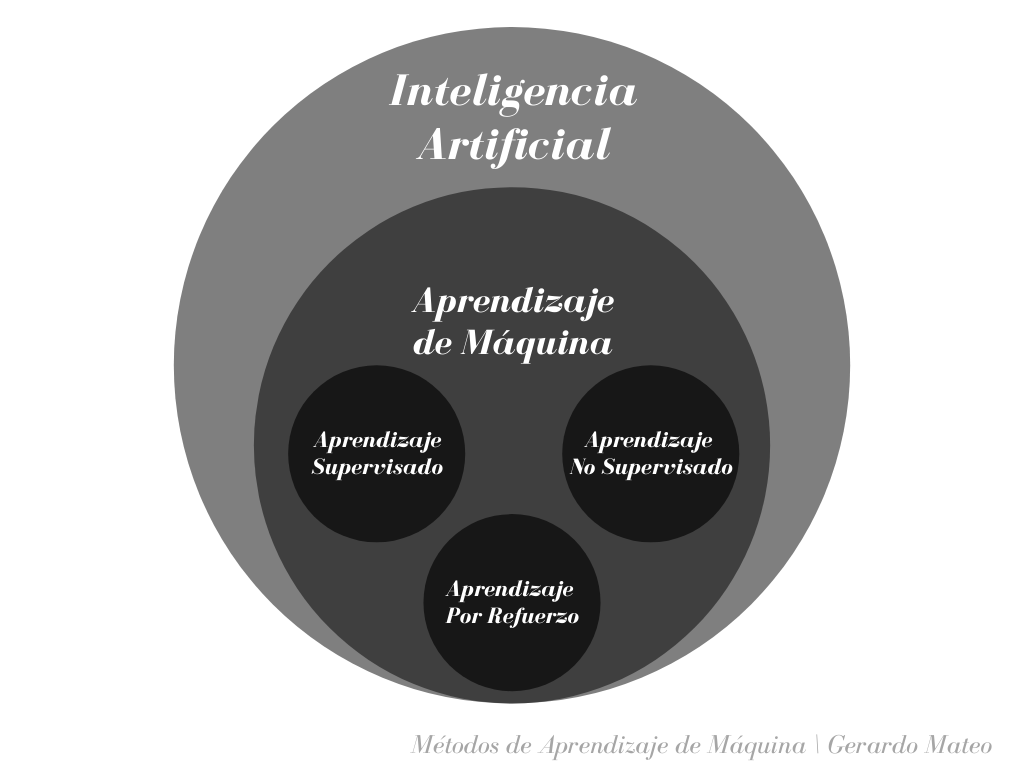
En el aprendizaje no supervisado, la máquina identifica patrones en data no etiquetada previamente, y trata de agruparla basada en propiedades similares. Un ejemplo de aprendizaje no supervisado es aplicado en los sistemas de recomendación de películas, donde se hacen recomendaciones basadas en películas vistas anteriormente, al identificar patrones similares en sus propiedades sin ninguna instrucción explícita previa. Por último, el aprendizaje por refuerzo se utiliza frecuentemente en videojuegos, donde la máquina aprende de sus errores poco a poco, y se mantiene en mejora continua hasta alcanzar un nivel de predicción alto basado en las estadísticas acumuladas durante el proceso de entrenamiento del algoritmo.
El aprendizaje de máquina ha optimizado tareas que hubieran tomado mucho más recursos para ser llevadas a cabo a través de un algoritmo tradicional, y eso se ha visto reflejado en la productividad y generación de ganancias significativas por parte de organizaciones privadas que lo aplican a sus productos y servicios. Según la firma consultora McKinsey & Company, la gestión de cadenas de suministro apalancadas por aprendizaje de máquina mejora en gran medida la precisión de los pronósticos y, al mismo tiempo, aumenta la granularidad y optimiza el reabastecimiento de inventario.
Éste puede permitir reducciones de entre un 20 y un 50 por ciento en los errores de pronóstico, y las ventas perdidas debido a que los productos no están disponibles se pueden reducir hasta en un 65%.
Operaciones gubernamentales
En los últimos tres años se ha visto un mayor interés por parte de los gobiernos en entender cómo la Inteligencia Artificial puede ser aplicada al sector público. En agosto de 2018 se estableció la Comisión de Seguridad Nacional sobre Inteligencia Artificial de los Estados Unidos, y en junio de 2020 se estableció su Comité actual. Por otro lado, en mayo de 2021 la Casa Blanca anunció el lanzamiento de la Iniciativa Nacional de Inteligencia Artificial, con el objetivo de ampliar los esfuerzos federales de innovación en Inteligencia Artificial, alentando al sector privado a trabajar conjuntamente con el gobierno en el diseño, desarrollo e implementación de soluciones públicas apalancadas por inteligencia artificial.
De acuerdo al último reporte de 2021 de la Comisión de Seguridad Nacional de Inteligencia Artificial de Estados Unidos, a pesar de que ha habido un interés inicial por parte del gobierno en la aplicación de Inteligencia Artificial para mejora de procesos, aún se necesita tomar acción masiva. También se destaca que el gobierno debe aliarse con el sector privado y las sociedades profesionales de investigación y desarrollo, para llevar a cabo una transformación expedita antes de 2025.
Para lograr una transformación en las operaciones gubernamentales, es fundamental para los gobiernos entender los elementos que permitieron esa misma transformación en el sector privado, siendo conscientes de que el sector público puede implementar las mejores prácticas del sector privado, pero debe desarrollar su propio conjunto de conocimientos técnicos. También es clave para ellos identificar usos más experimentales de aprendizaje de máquina para tareas más complejas que solo se encuentran en el sector público.
En los últimos años, hemos estado observando y estudiando aplicaciones experimentales de aprendizaje de máquina en la optimización de procesos de compras gubernamentales, después de haber conversado con cientos de agencias gubernamentales a nivel local y federal en Estados Unidos, y en Latinoamérica, hemos descubierto que a pesar de que los empleados públicos encargados de realizar compras en las distintas agencias gubernamentales cuentan con bases de datos de suplidores registrados, contratos y licitaciones, es complicado y les toma bastante tiempo entender dónde encontrar lo que necesitan.
Hemos descubierto que existe una gran fragmentación en los sistemas que informan las adquisiciones del gobierno, específicamente, sus sistemas de almacenamiento, sus bases de datos de contratos, sus bases de datos de proveedores registrados, y las calificaciones y comentarios de sus proveedores existentes. Esta fragmentación crea una limitación de saber si realmente están comprando al mejor precio del mercado en el momento de realizar una compra. Para el gobierno poder hacer una compra pequeña o grande que esté apegada a la ley, tiene que realizar una evaluación exhaustiva y comparar distintos pedazos de información que no están conectados ni han sido actualizados en meses o años, por lo que la decisión tomada cuando se realiza una compra, es subóptima.
Los humanos no podemos procesar grandes cantidades de datos manualmente, pero el Aprendizaje de Máquina sobresale en tareas que están claramente definidas e involucran cantidades masivas de datos. Para atacar ese problema, hemos estado estudiando y trabajando en el desarrollo inicial de un algoritmo que aplica aprendizaje no supervisado para asistir a los equipos de compras públicas.
Específicamente estamos preparando un modelo estadístico creado a partir de data pública de compras gubernamentales recurrentes, organizando los casos de compras con propiedades similares, sincronizando bases de datos donde se almacena la información relevante para el comprador, y habilitando una interfaz capaz de ayudarle a encontrar lo que necesita de forma sencilla.
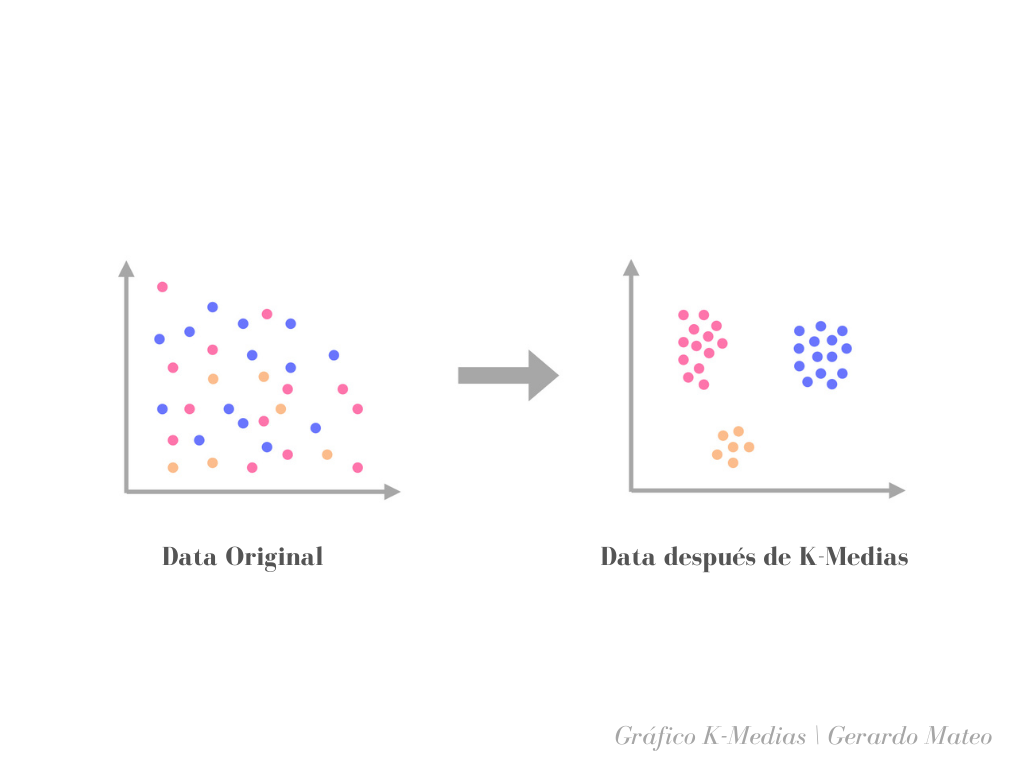
A través del método K-Medias o K-means en inglés, un método de agrupamiento de cuantificación vectorial que divide observaciones en grupos, buscamos agrupar automáticamente expresiones semánticamente similares y así acelerar la derivación y verificación de la intención de un usuario común. De esta forma un usuario autorizado puede simplemente decir lo que necesita, y el algoritmo identifica si eso está disponible en el almacén de la agencia, en un contrato existente, en su lista de suplidores registrados, o en el mercado abierto.
Con esta arquitectura, el algoritmo es capaz de hacer un análisis expedito capa por capa, de encontrar lo que el usuario necesita, independientemente de en cuál capa se encuentre, y de permitirle al usuario hacer la compra de forma inmediata, con el mismo nivel de cumplimiento con las regulaciones de compras públicas que el proceso manual.
En el contexto de análisis predictivo para compras públicas, el algoritmo podría tomar una muestra de compras pasadas e intuitivamente dividirla en múltiples grupos separados, tomando en cuenta propiedades como: rango de precio, categoría de producto, fecha límite, frecuencia de compra, entre otras, y basándose en las similitudes, sugerir la opción de compra ideal de forma instantánea.
¿Cuándo veremos el aprendizaje de máquina en el sector público a gran escala?
El uso del Aprendizaje de Máquina en las operaciones gubernamentales tiene el potencial de reducir la carga de trabajo de los empleados públicos en tareas repetitivas, permitiendo la mejora de sus procesos y brindando mayor precisión en los resultados; sin embargo, no es algo que se debe aplicar deliberadamente a todos los procesos.
Mi experiencia trabajando en el estudio, preparación y desarrollo inicial de algoritmos de Aprendizaje de Máquina para el sector público me ha dejado tres aprendizajes principales hasta ahora:
1. El aprendizaje de máquina no es la solución para todo tipo de tareas en el sector público. Por el momento es ideal para tareas pequeñas, repetitivas e incrementales.
2. Hay que empezar pequeño. Antes de asignar recursos y amplificar un proyecto que involucre Aprendizaje de Máquina, se debe ejecutar una fase de preparación y ensayos experimentales basado en una hipótesis inicial, e ir refinando poco a poco.
3. La data es la clave. Para que un algoritmo de aprendizaje de máquina sea eficiente, se necesita acceso a mucha data, y que esta sea de calidad, por lo que el trabajo previo de recolección y limpieza de la data es esencial antes de la creación de un modelo predictivo.
Comenzar pequeño es clave, pero el impacto del aprendizaje de máquina como herramienta para los gobiernos es grande. Un ejemplo es la predicción de la congestión de tráfico. La congestión de tráfico es un gran problema en las grandes ciudades, y es muy difícil de predecir. Muchos gobiernos alrededor del mundo están utilizando métodos de Aprendizaje de Máquina para predecir las condiciones del tráfico a corto plazo, con una precisión de predicción estimada del 90%, lo que ayuda al personal de los gobiernos a tomar medidas proactivas para aliviar la congestión del tráfico en las áreas más concurridas de la infraestructura de transporte de una ciudad.
El interés de los gobiernos en utilizar Aprendizaje de Máquina para el sector público ya existe. Ahora el próximo paso es que las agencias aprendan de las metodologías que ya han sido perfeccionadas por el sector privado, y crear alianzas estratégicas que permitan una transformación real que se pueda ver a corto, mediano y largo plazo.











